来源:[db:来源] 时间:2022-06-15 14:31:37
专题介绍
2009 年,Spark 诞生于加州大学伯克利分校的 AMP 实验室(the Algorithms, Machines and People lab),并于 2010 年开源。2013 年,Spark 捐献给阿帕奇软件基金会(Apache Software Foundation),并于 2014 年成为 Apache 顶级项目。
如今,十年光景已过,Spark 成为了大大小小企业与研究机构的常用工具之一,依旧深受不少开发人员的喜爱。如果你是初入江湖且希望了解、学习 Spark 的“小虾米”,那么 InfoQ 与 FreeWheel 技术专家吴磊合作的专题系列文章——《深入浅出 Spark:原理详解与开发实践》一定适合你!
本文系专题系列第二篇。
书接前文,在上一篇《内存计算的由来 —— RDD》,我们从“虚”、“实”两个方面介绍了RDD 的基本构成。RDD 通过dependencies 和compute 属性首尾相连构成的计算路径,专业术语称之为Lineage —— 血统,又名DAG(Directed Acyclic Graph,有向无环图)。一个概念为什么会有两个称呼呢?这两个不同的名字又有什么区别和联系?简单地说,血统与DAG 是从两个不同的视角出发,来描述同一个事物。血统,侧重于从数据的角度描述不同RDD 之间的依赖关系;DAG,则是从计算的角度描述不同RDD 之间的转换逻辑。如果说RDD 是Spark 对于分布式数据模型的抽象,那么与之对应地,DAG 就是Spark 对于分布式计算模型的抽象。
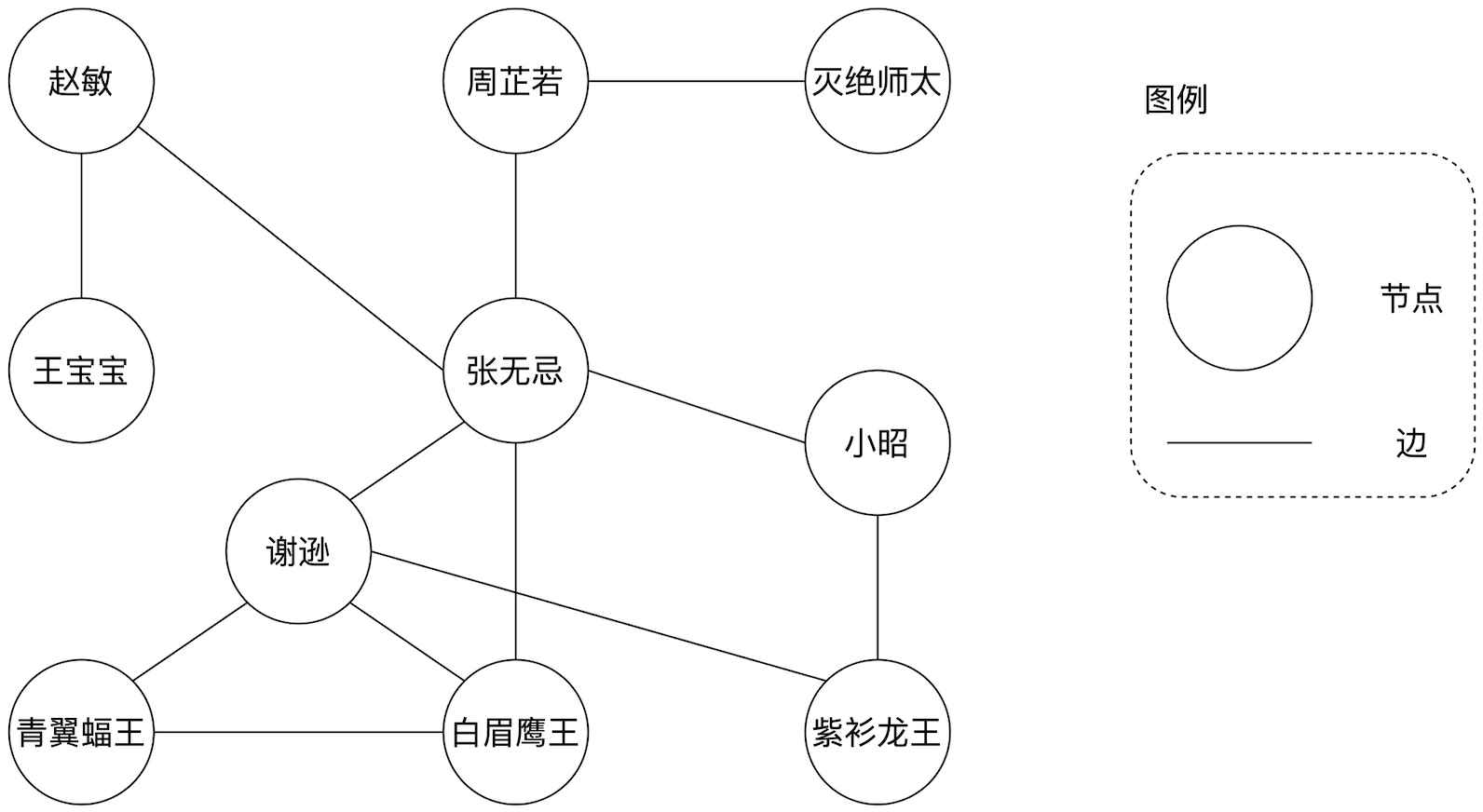
顾名思义,DAG 是一种“图”,图计算模型的应用由来已久,早在上个世纪就被应用于数据库系统(Graph databases)的实现中。任何一个图都包含两种基本元素:节点(Vertex)和边(Edge),节点通常用于表示实体,而边则代表实体间的关系。例如,在“倚天屠龙”社交网络的好友关系中,每个节点表示一个具体的人,每条边意味着两端的实体之间建立了好友关系。
倚天屠龙社交网络
在上面的社交网络中,好友关系是相互的,如张无忌和周芷若互为好友,因此该关系图中的边是没有指向性的;另外,细心的同学可能已经发现,上面的图结构是有“环”的,如张无忌、谢逊、白眉鹰王构成的关系环,张无忌、谢逊、紫衫龙王、小昭之间的关系环,等等。像上面这样的图结构,术语称之为“无向有环图”。没有比较就没有鉴别,有向无环图(DAG)自然是一种带有指向性、不存在“环”结构的图模型。各位看官还记得土豆工坊的例子吗?
土豆工坊DAG
在上面的土豆加工DAG 中,每个节点是一个个RDD,每条边代表着不同RDD 之间的父子关系 —— 父子关系自然是单向的,因此整张图是有指向性的。另外我们注意到,整个图中是不存在环结构的。像这样的土豆加工流水线可以说是最简单的有向无环图,每个节点的入度(Indegree,指向自己的边)与出度(Outdegree,从自己出发的边)都是1,整个图看下来只有一条分支。
不过,工业应用中的Spark DAG 要比这复杂得多,往往是由不同RDD 经过关联、拆分产生多个分支的有向无环图。为了说明这一点,我们还是拿土豆工坊来举例,在将“原味”薯片推向市场一段时间后,工坊老板发现季度销量直线下滑,老板心急如焚、一筹莫展。此时有人向他建议:“何不推出更多风味的薯片,来迎合大众的多样化选择”,于是老板一声令下,工人们对流水线做了如下改动。
土豆工坊高级生产线
与之前相比,新的流程增加了3 条风味流水线,用于分发不同的调料粉。新流水线上的辣椒粉被分发到收集小号薯片的流水线、孜然粉分发到中号薯片流水线,相应地,番茄粉分发到大号薯片流水线。经过改造,土豆工坊现在可以生产3 种风味、不同尺寸的薯片,即麻辣味的小号薯片、孜然味的中号薯片和番茄味的大号薯片。如果我们用flavoursRDD 来抽象调味品的话,那么工坊新作业流程所对应的DAG 会演化为如下所示带有2 个分支的有向无环图。
多个分支的DAG
在上一篇,我们探讨了Spark Core 内功心法的第一要义 —— RDD,这一篇,咱们来说说内功心法的第二个秘诀 —— DAG。
在上一篇《内存计算的由来 —— RDD》最后,我们以 WordCount 为例展示不同 RDD 之间转换而形成的 DAG 计算图。通读代码,从开发的角度来看,我们发现 DAG 构成的关键在于 RDD 算子调用。不同于 Hadoop MapReduce,Spark 以数据为导向提供了丰富的 RDD 算子,供开发者灵活地排列组合,从而实现多样化的数据处理逻辑。那么问题来了,Spark 都提供哪些算子呢?
数据来源: https://spark.apache.org/docs/latest/rdd-programming-guide.html
从表格中我们看到,Spark 的 RDD 算子丰富到让人眼花缭乱的程度,对于初次接触 Spark 的同学来说,如果不稍加归类,面对多如繁星的算子还真是无从下手。Apache Spark 官网将 RDD 算子归为 Transformations 和 Actions 两种类型,这也是大家在各类 Spark 技术博客中常见的分类方法。为了说明 Transformations 和 Actions 算子的本质区别,我们必须得提一提 Spark 计算模型的“惰性计算”(Lazy evaluation,又名延迟计算)特性。
掌握一个新概念最有效的方法之一就是找到与之相对的概念 —— 与“惰性计算”相对,大多数传统编程语言、编程框架的求值策略是“及早求值”(Eager evaluation)。例如,对于我们熟悉的 C、C 、Java 来说,每一条指令都会尝试调度 CPU、占用时钟周期、触发计算的执行,同时,CPU 寄存器需要与内存通信从而完成数据交换、数据缓存。在传统编程模式中,每一条指令都很“急”(Eager),都恨不得自己马上被调度到“前线”、参与战斗。
惰性计算模型则不然 —— 具体到 Spark,绝大多数 RDD 算子都很“稳”、特别能沉得住气,他们会明确告诉 DAGScheduler:“老兄,你先往前走着,不用理我,我先绷会儿、抽袋烟。队伍的前排是我们带头大哥,没有他的命令,我们不会贸然行动。”有了惰性计算和及早求值的基本了解,我们再说回 Transformations 和 Actions 的区别。在 Spark 的 RDD 算子中,Transformations 算子都属于惰性求值操作,仅参与 DAG 计算图的构建、指明计算逻辑,并不会被立即调度、执行。惰性求值的特点是当且仅当数据需要被物化(Materialized)时才会触发计算的执行,RDD 的 Actions 算子提供各种数据物化操作,其主要职责在于触发整个 DAG 计算链条的执行。当且仅当 Actions 算子触发计算时, DAG 从头至尾的所有算子(前面用于构建 DAG 的 Transformations 算子)才会按照依赖关系的先后顺序依次被调度、执行。
说到这里,各位看官不禁要问:Spark 采用惰性求值的计算模型,有什么优势吗?或者反过来问:Spark 为什么没有采用传统的及早求值?不知道各位看官有没有听说过“延迟满足效应”(又名“糖果效应”),它指的是为了获取长远的、更大的利益而自愿延缓甚至放弃目前的、较小的满足。正所谓:“云想衣裳花想容,猪想发福人想红”。Spark 这孩子不仅天资过人,小小年纪竟颇具城府,独创的内功心法意不在赢得眼下的一招半式,而是着眼于整个武林。扯远了,我们收回来。笼统地说,惰性计算为 Spark 执行引擎的整体优化提供了广阔的空间。关于惰性计算具体如何帮助 Spark 做全局优化 —— 说书的一张嘴表不了两家事,后文书咱们慢慢展开。
还是说回 RDD 算子,除了常见的按照 Transformations 和 Actions 分类的方法,笔者又从适用范围和用途两个维度为老铁们做了归类,毕竟人类的大脑喜欢结构化的知识,官网上一字长蛇阵的罗列总是让人看了昏昏欲睡。有了这个表格,我们就知道 *ByKey 的操作一定是作用在 Paired RDD 上的,所谓 Paired RDD 是指 Schema 明确区分(Key, Value)对的 RDD,与之相对,任意 RDD 指的是不带 Schema 或带任意 Schema 的 RDD。从用途的角度来区分 RDD 算子的归类相对比较分散,篇幅的原因,这里就不一一展开介绍,老铁们各取所需吧。
值得一提的是,对于相同的计算场景,采用不同算子实现带来的执行性能可能会有天壤之别,在后续的性能调优篇咱们再具体问题具体分析。好吧,坑越挖越多,列位看官您稍安勿躁,咱们按照 FIFO 的原则,先来说说刚刚才提到的、还热乎的 DAGScheduler。
DAGScheduler 是 Spark 分布式调度系统的重要组件之一,其他组件还包括 TaskScheduler、MapOutputTracker、SchedulerBackend 等。DAGScheduler 的主要职责是根据 RDD 依赖关系将 DAG 划分为 Stages,以 Stage 为粒度提交任务(TaskSet)并跟踪任务进展。如果把 DAG 看作是 Spark 作业的执行路径或“战略地形”,那么 DAGScheduler 就是这块地形的向导官,这个向导官负责从头至尾将地形摸清楚,根据地形特点排兵布阵。更形象地,回到土豆工坊的例子,DAGScheduler 要做的事情是把抽象的土豆加工 DAG 转化为工坊流水线上一个个具体的薯片加工操作任务。那么问题来了,DAGScheduler 以怎样的方式摸索“地形”?如何划分 Stages?划分 Stages 的依据是什么?更进一步,将 DAG 划分为 Stages 的收益有哪些?Spark 为什么要这么做?
DAGScheduler 的核心职责
为了回答这些问题,我们需要先对于 DAG 的“首”和“尾”进行如下定义:在一个 DAG 中,没有父 RDD 的节点称为首节点,而没有子 RDD 的节点称为尾节点。还是以土豆工坊为例,其中首节点有两个,分别是 potatosRDD 和 flavoursRDD,而尾节点是 flavouredBakedChipsRDD。
DAG 中首与尾的定义
DAGScheduler 在尝试探索 DAG“地形”时,是以首尾倒置的方式从后向前进行。具体说来,对于土豆工坊的 DAG,DAGScheduler 会从尾节点 flavouredBakedChipsRDD 开始,根据 RDD 依赖关系依次向前遍历所有父 RDD 节点,在遍历的过程中以 Shuffle 为边界划分 Stage。Shuffle 的字面意思是“洗牌”,没错,就是扑克游戏中的洗牌,在大数据领域 Shuffle 引申为“跨节点的数据分发”,指的是为了实现某些计算逻辑需要将数据在集群范围内的不同计算节点之间定向分发。在绝大多数场景中,Shuffle 都是当之无愧的“性能瓶颈担当”,毫不客气地说,有 Shuffle 的地方,就有性能优化的空间。关于 Spark Shuffle 的原理和性能优化技巧,后面我们会单独开一篇来专门探讨。在土豆工坊的 DAG 中,有两个地方发生了 Shuffle,一个是从 bakedChipsRDD 到 flavouredBakedChipsRDD 的计算,另一个是从 flavoursRDD 到 flavouredBakedChipsRDD 的计算,如下图所示。
土豆工坊 DAG 中的 Shuffle
各位看官不禁要问:DAGScheduler 如何判断 RDD 之间的转换是否会发生 Shuffle 呢?那位看官说了:“前文书说了半天算子是 RDD 之间转换的关键,莫不是根据算子来判断会不会发生 Shuffle?”您还真猜错了,算子与 Shuffle 没有对应关系。就拿 join 算子来说,在大部分场景下,join 都会引入 Shuffle;然而在 collocated join 中,左右表数据分布一致的情况下,是不会发生 Shuffle 的。所以您看,DAGScheduler 还真不能依赖算子本身来判断发生 Shuffle 与否。要回答这个问题,咱们还是得回到前文书《内存计算的由来 —— RDD》中介绍 RDD 时提到的 5 大属性。
属性名 成员类型 属性含义 dependencies 变量 生成该 RDD 所依赖的父 RDD compute 方法 生成该 RDD 的计算接口 partitions 变量 该 RDD 的所有数据分片实体 partitioner 方法 划分数据分片的规则 preferredLocations 变量 数据分片的物理位置偏好
RDD 的 5 大属性及其含义
其中第一大属性 dependencies 又可以细分为 NarrowDependency 和 ShuffleDependency,NarrowDependency 又名“窄依赖”,它表示 RDD 所依赖的数据无需分发,基于当前现有的数据分片执行 compute 属性封装的函数即可;ShuffleDependency 则不然,它表示 RDD 依赖的数据分片需要先在集群内分发,然后才能执行 RDD 的 compute 函数完成计算。因此,RDD 之间的转换是否发生 Shuffle,取决于子 RDD 的依赖类型,如果依赖类型为 ShuffleDependency,那么 DAGScheduler 判定:二者的转换会引入 Shuffle。在回溯 DAG 的过程中,一旦 DAGScheduler 发现 RDD 的依赖类型为 ShuffleDependency,便依序执行如下 3 项操作:
沿着 Shuffle 边界的子 RDD 方向创建新的 Stage 对象把新建的 Stage 注册到 DAGScheduler 的 stages 系列字典中,这些字典用于存储、记录与 Stage 有关的状态和元信息,以备后用沿着当前 RDD 的父 RDD 遵循广度优先搜索算法继续回溯 DAG拿土豆工坊来说,其尾节点 flavouredBakedChipsRDD 同时依赖 bakedChipsRDD 和 flavoursRDD 两个父 RDD,且依赖类型都是 ShuffleDependency,那么依据 DAGScheduler 的执行逻辑,此时会执行如下 3 项具体操作:
DAGScheduler 回溯 DAG 过程当中遇到 ShuffleDependency 时的主要操作流程
DAGScheduler 沿着尾节点回溯并划分出 stage0
在完成第一个 Stage(stage0)的创建和注册之后,DAGScheduler 先沿着 bakedChipsRDD 方向继续向前回溯。在沿着这条路向前跑的时候,我们的这位 DAGScheduler 向导官惊喜地发现:“我去!这一路上一马平川、风景甚好,各个驿站之间什么障碍都没有,交通甚是顺畅,真是片好地形!”—— 沿路遇到的所有 RDD(bakedChipsRDD,chipsRDD,cleanedPotatosRDD,potatosRDD)的依赖类型都是 NarrowDependency。
在回溯完毕时,DAGScheduler 同样会重复上述 3 个步骤,根据 DAGScheduler 以 Shuffle 为边界划分 Stage 的原则,沿途的所有 RDD 都划归为同一个 Stage,暂且记为 stage1。值得一提的是,Stage 对象的 rdd 属性对应的数据类型是 RDD[],而不是 List[RDD[]]。对于一个逻辑上包含多个 RDD 的 Stage 来说,其 rdd 属性存储的是路径末尾的 RDD 节点,具体到我们的案例中就是 bakedChipsRDD。
DAGScheduler 沿着 bakedChipsRDD 方向回溯并划分出 stage1
勤勤恳恳的 DAGScheduler 在成功创建 stage1 之后,依然不忘初心、牢记使命,继续奔向还未探索的路线。从上图中我们清楚地看到整块地形还剩下 flavoursRDD 方向的路径没有纳入 DAGScheduler 的视野范围。咱们的这位 DAGScheduler 向导官记性相当得好,早在划分 stage0 的时候,他就用小本子(栈)记下:“此路口有分叉,先沿着 bakedChipsRDD 方向走,然后再回过头来沿着 flavoursRDD 的方向探索。切记,切记!”此时,向导大人拿出之前的小本子,用横线把 bakedChipsRDD 方向的路径划掉 —— 表示该方向路径已探索过,然后沿着 flavoursRDD 方向大踏步地走下去。一脚下去,发现:“我去!到头儿了!”,然后紧接着执行一贯的“三招一套”流程 —— 创建 Stage、注册 Stage、继续回溯。随着 DAGScheduler 创建最后一个 Stage:stage2,地形上的所有路径都已探索完毕。
DAGScheduler 创建最后一个 Stage:stage2
到此为止,我们的向导大人几乎跑断了腿、以首尾倒置的顺序对整片地形进行了地毯式搜查,最终将地形划分为 3 块战略区域(Stage)。那么问题来了,向导大人划分出的 3 块区域,有啥用呢?DAGScheduler 他老人家马不停蹄地这么跑,到底图啥?前面我们提到,DAGScheduler 的核心职责,是将抽象的 DAG 计算图转换为具体的、可并行计算的分布式任务。回溯 DAG、创建 Stage,只是这个核心职责的第一步,DAGScheduler 以 Stage(TaskSet)为粒度进行任务调度,伙同 TaskScheduler、SchedulerBackend 等一众大佬运筹帷幄、调兵遣将。不过,毕竟本篇的主题是 DAG,到 Spark 调度系统的核心还有些距离,因此这里咱们暂且挖个坑,后面再单独开篇(Spark 调度系统)专门讲述几位大佬之间的趣事逸闻。填坑之路漫漫其修远兮,吾将上下而挖坑。
咱们来回顾一下向导大人的心路历程,首先,DAGScheduler 沿着 DAG 的尾节点一路北上,并沿途判断每一个 RDD 节点的 dependencies 属性。之后,如果判定 RDD 的 dependencies 属性是 NarrowDependency,则 DAGScheduler 继续向前回溯;若 RDD 的依赖是 ShuffleDependency,DAGScheduler 便开启“三招一套”的招式,创建 Stage、注册 Stage 并继续向前回溯。由此可见,何时切割 DAG 并生成新的 Stage 由 RDD 的依赖类型决定,当且仅当 RDD 的依赖是 ShuffleDependency 时,DAGScheduler 才会新建 Stage。
喜欢刨根问底的您一定会问:“DAGScheduler 怎么知道 RDD 的依赖类型到底是哪一个?他怎么判别 RDD 的依赖是窄依赖还是 ShuffleDependency?”要回答这个问题,我们就还得回到 RDD 的 5 大属性上,不过这次出场的是 partitioner。还记得这个属性吗?partitioner 是 RDD 的分区器、定义了 RDD 数据分片的分区规则,它决定了 RDD 的数据分片在分布式集群中如何分布,这个属性至关重要,后面介绍 Shuffle 的时候我们还会提到它。DAGScheduler 正是通过 partitioner 来判定每个 RDD 的依赖类型,具体来说,如果子 RDD 的 partitioner 与父 RDD 的 partitioner 一致,那么 DAGScheduler 判定子 RDD 对父 RDD 的依赖属于窄依赖;相反,如果两者 partitioner 不一致,也即分区规则不同(分区规则不同则意味着一定存在数据的“重洗牌”,即 Shuffle),那么 DAGScheduler 判定子对父的依赖关系是 ShuffleDependency。到此,DAGScheduler 对于 DAG 的划分逻辑可以暂且告一段落。原理说了,例子举了,还缺啥?对!代码。
古人云:“光说不练假把式”,我们用一个小例子来展示一下 DAG 与 Stage 的关系。还是用上篇《内存计算的由来 —— RDD》中的 WordCount 依样画葫芦,文件内容如下。
示例文件内容
代码也没变:
WordCount 示例代码
虽然文件内容和代码都没变,但是我们观察问题的视角变了,这次我们关心的是 DAG 中 Stage 的划分以及 Stage 之间的关系。RDD 的 toDebugString 函数让我们可以一览 DAG 的构成以及 Stage 的划分,如下图所示。
DAG 构成及 Stage 划分
在上图中,从第 3 行往下,每一行表示一个 RDD,很显然,第 3 行的 ShuffledRDD 是 DAG 的尾节点,而第 7 行的 HadoopRDD 是首节点。我们来观察每一行字符串打印的特点,首先最明显地,第 4、5、6、7 行的前面都有个制表符(Tab),与第 3 行有个明显的错位,这表示第 3 行的 ShuffledRDD 被划分到了一个 Stage(记为 stage0),而第 4、5、6、7 行的其他 RDD 被划分到了另外一个 Stage(记为 stage1),且 stage0 对 stage1 有依赖关系。假设第 7 行下面的 RDD 字符串打印有两个制表符,即与第 7 行产生错位,那么第 7 行下面的 RDD 则被划到了新的 Stage,以此类推。
由此可见,通过 RDD 的 toDebugString 观察 DAG 的 Stage 划分时,制表符是个重要的指示牌。另外,我们看到第 3、4 行的开头都有个括号,括号里面是数字,这个数字标记的是 RDD 的 partitions 大小。当然了,观察 RDD、DAG、Stage 还有更直观的方式,Spark 的 Web UI 提供了更加丰富的可视化信息,不过 Spark 的 Web UI 面板繁多,对于新同学来说一眼望去反而容易不知所措,也许后面时间允许的话我们单开一篇 Spark Web UI 的串讲。
本篇是《Spark 分布式计算科普专栏》的第二篇,笔者学浅才疏、疏漏难免。如果您有任何疑问,或是觉得文章中的描述有所遗漏或不妥,欢迎在评论区留言、讨论。掌握一门技术,书本中的知识往往只占两成,三成靠讨论,五成靠实践。更多的讨论能激发更多的观点、视角与洞察,也只有这样,对于一门技术的认知与理解才能更深入、牢固。
在本篇博文中,我们从 DAG 的边 —— Spark RDD 算子入手,介绍了衔接 RDD 的两大类算子:Transformations 和 Actions,并对惰性计算有了初步的认知。然后,还是以土豆工坊为例,介绍 DAGScheduler 切割 DAG、生成 Stage 的流程和步骤,尤其需要注意的是 DAGScheduler 以 Shuffle 为边界划分 Stage。
最后,用上一篇的 WordCount 简单展示了 DAG 与 Stage 的关系。细心的读者可能早已发现,文中多次提及“后文书再展开”、“后面再单开一篇”,Spark 是一个精妙而复杂的分布式计算引擎,在本篇博文中我们不得不对 Spark 中的许多概念都进行了“前置引用”。换句话说,有些概念还没来得及解释(如惰性计算、Shuffle、TaskScheduler、TaskSet、Spark 调度系统),就已经被引入到了本篇博文中。这样的叙述方法也许会给您带来困惑,毕竟,用一个还未说清楚的概念,去解释另一个新概念,总是感觉没那么牢靠。
常言道:“杀人偿命、欠债还钱”,在后续的专栏文章中,我们会继续对 Spark 的核心概念与原理进行探讨,慢慢地把欠您的技术债还上,尽可能地还原 Spark 分布式内存计算引擎的全貌。毕竟 Spark 调度系统为何方神圣,DAGScheduler 伙同 TaskScheduler、SchedulerBackend、TaskSetManager 等一众大佬如何演绎权利的游戏,且听下回分解。
作者简介
吴磊,Spark Summit China 2017 讲师、World AI Conference 2020 讲师,曾任职于 IBM、联想研究院、新浪微博,具备丰富的数据库、数据仓库、大数据开发与调优经验,主导基于海量数据的大规模机器学习框架的设计与实现。现担任 Comcast Freewheel 机器学习团队负责人,负责计算广告业务中机器学习应用的实践、落地与推广。热爱技术分享,热衷于从生活的视角解读技术,曾于《IBM developerWorks》和《程序员》杂志发表多篇技术文章。
延伸阅读:
深入浅出Spark(一):内存计算的由来-InfoQ
我并转发此篇文章,私信我“领取资料”,即可免费获得InfoQ价值4999元迷你书,点击文末「了解更多」,即可移步InfoQ官网,获取最新资讯~
相关推荐
猜你喜欢




